Decide Module¶
This graphical abstract represents an intelligent network management system using a reinforcement learning-based approach for dynamic network control. The framework integrates ONOS (Open Network Operating System) with a DQN (Deep Q-Network) agent for optimizing traffic management based on observed network conditions.
The system begins by retrieving network state data from the ONOS controller through its REST API. This network data is represented by the traffic matrix TMt, which consists of link utilization ui,t and latency li,t values between different network devices. Latency measurements are critical for understanding traffic delays between specific source and destination pairs. The matrix captures both current link utilization and latency for each time step t, providing a real-time snapshot of network performance.
Once the network traffic state is captured, the next step involves feeding this data into a DQN model. The DQN agent processes the network state as an input and outputs an action at, which consists of a set of potential actions, including path re-routing policies and traffic throttling strategies based on service type.
From the decision-making loop, where the DQN evaluates the current network state and decides whether or not to take corrective actions. These actions could include rerouting traffic to mitigate congestion, balancing loads across network links, or throttling low-priority traffic. The process is iterative, meaning the agent continually observes, evaluates, and updates its decisions based on new network data.
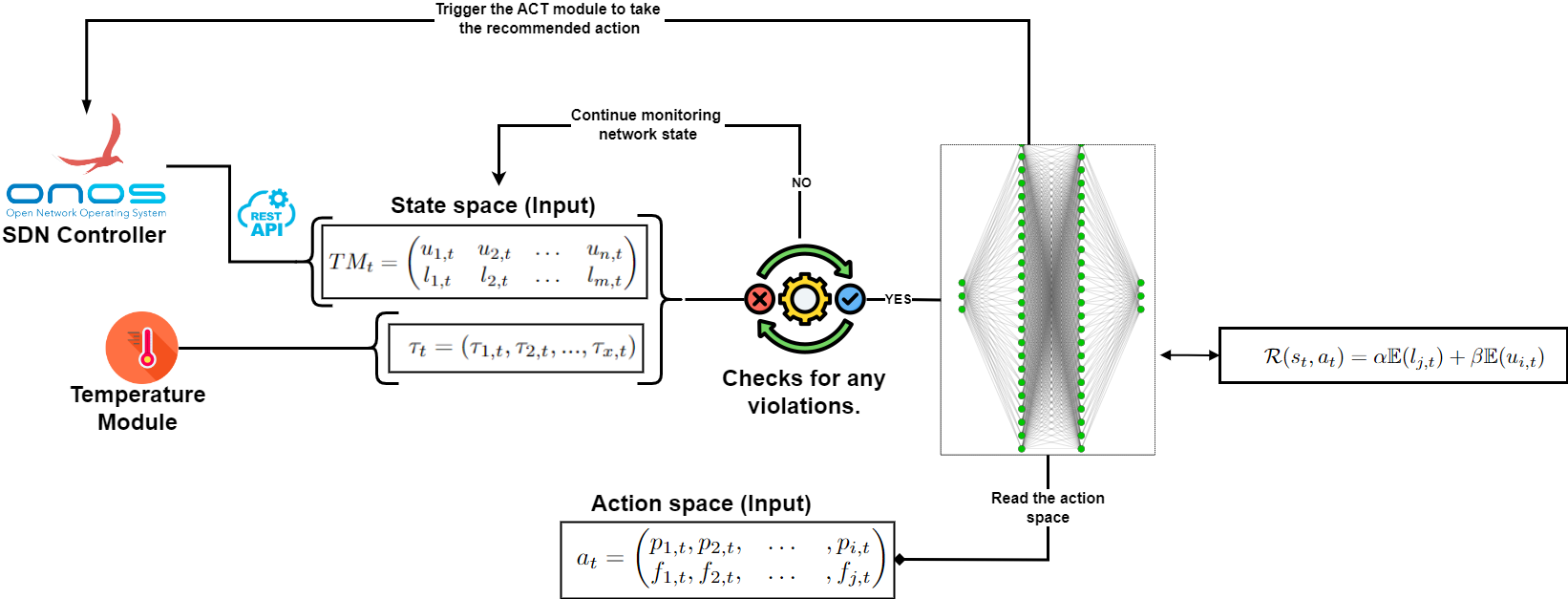
The learning process for the DQN agent is guided by a reward function R(st, at), which is illustrated in the bottom right of the diagram. This reward function is designed to incentivize actions that optimize network performance by minimizing latency and maximizing utilization. The reward is computed using a weighted sum of latency lj,t and utilization ui,t, with tunable parameters α and β representing the importance of each metric. The goal is to adjust network operations to meet predefined system intents, which are captured as normalized thresholds for various performance metrics.
Once an action is taken by the system, the network state is continuously monitored to evaluate its impact. If the action taken by the DQN does not result in the desired performance improvements, the system can readjust by selecting a different action in the next iteration. This closed-loop process ensures the network adapts dynamically to changing conditions, whether due to traffic fluctuations or external factors such as device failures or cyber-attacks.
The Decide module python script can be found here